
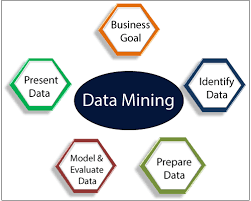
Data Mining is an essential branch of computer science. It is a process of extracting useful information or knowledge from huge data. There is a gap between data and intake, which can be reduced using several data mining tools. This can also be referred to as Knowledge discovery from data.
Data mining can be performed on various databases and information repositories, such as relational databases, data warehouses, transactional databases, data streams, and much more.
Types of Data Mining
Anyone can perform the process of data mining on the following types of data.
- Smoothning: Smoothning is the preparation part of the data. The main intent is to remove the noise from the data. The algorithms are simple exponential. During the exploratory analysis, this technique is convenient to visualise the trends and sentiments.
- Aggregation: In this process, a group of data is aggregated to achieve information. It is done to overview the business objectives so that they can be performed manually or by using some specialized software.
- Generalization: It is a technique that is done to generalize data as a whole. This data is not grouped to achieve information. It enables a data science model to adapt to newer data points.
- Normalization: Special care is employed to the data points in this technique, which helps to bring the data in the same scale for analysis.
- Attribute: This technique is also known as feature selection. The methods are employed to select features so that the model is used to train the data. These data sets can imply the value t predict the data which haven’t been seen.
- Classification: As the name suggests, in this the data is specified into classes. The collective features are selected so that it will become easy to specify them.
- Pattern Tracking: It is the basic technique that is used in data mining to get information about trends and patterns which the data points might exhibit.
- Outlier Analysis: Outlier analysis or anomaly detection is used to find or analyse the outliers or anomalies. These are something that stands out from the entire trend of the data set. We can remove them completely once we recognise them. Else this technique is extensively used in the model datasets to predict the outliners as well.
- Clustering: This technique is similar to classification, the only difference is that we are unaware of the group in which the data points will fall after the collection of the features. This method is mostly used in grouping people to target similar product recommendations.
- Regression: we use it to predict the likelihood of the features with the presence of other features.
- Neural Network: It is based on the principle of working biological neurons. It is similar to the working of neurons in the human body. The neurons in the neural network in data mining also work as the processing unit and connecting another neuron to pass on the information.
- Association: we determie the relationship between features in this method. We also use it to find hidden patterns or related analyses. The user can performe according to the business requirement.

